
Understanding Scraping Amazon Product Data
Scraping Amazon product data is the process of importing data from Amazon into another place, such as spreadsheets or other file formats. It can be used for personal use or business use cases.
Amazon product data you can scrape includes product-specific information, pricing details, seller ratings, customer reviews, etc. These details can help you understand the market and consumer sentiment according to your niche.
Pay attention to these while scraping Amazon product data:
- Review Amazon's terms of service and ensure your scraping activities align with ethical guidelines.
- Don't aggressively scrape without considering guidelines, and always respect intellectual property rights and user privacy to comply with regulations.
- You might use a User-Agent head in HTTP requests to avoid detection and reduce the risk of being flagged by anti-scraping mechanisms.
- To prevent being blocked during product data scraping, you can use proxy servers and improve anonymity.
- You may need to apply additional strategies for CAPTCHAs and JavaScript challenges while scraping data. To handle these, consider using additional services.
- You might need to regularly update your script to adapt to modifications if you want to do scraping manually, as website structure can change.
How to Scrape Amazon Product Data?
You can scrape Amazon product data by setting up a web scraping environment in Python, inspecting the web page, writing related scripts, and handling pagination.
These steps require manual actions related to programming and coding experience.
If you don't want to put time and energy into manually scraping Amazon product data, you can use a tool that helps you speed up the process.
There are various tools available that allow you to scrape Amazon product data. Some of the popular tools with this capability are Bright Data, Oxylabs, and Apify.
In this guide, we will explain how to scrape Amazon product data using Bright Data's Scraping Browser quickly and easily.
Follow these steps after creating your account and signing in:
Step 1: Navigate to the Proxies & Scraping Infrastructure page. Then, from the "Scraping Browser" part, click the "Get Started" button.
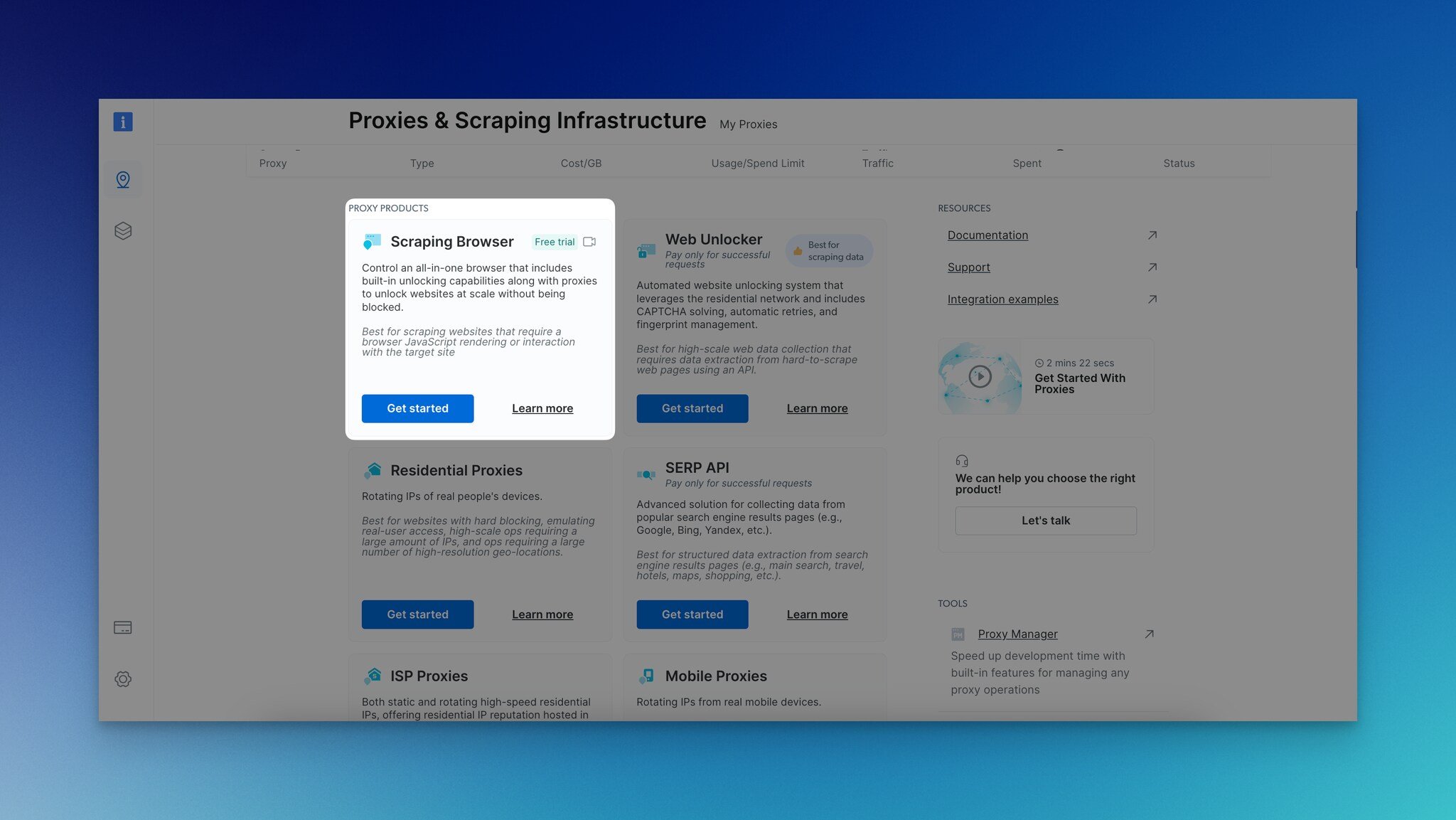
Step 2: Enter a name for your scraping browser and click the “Add” button.
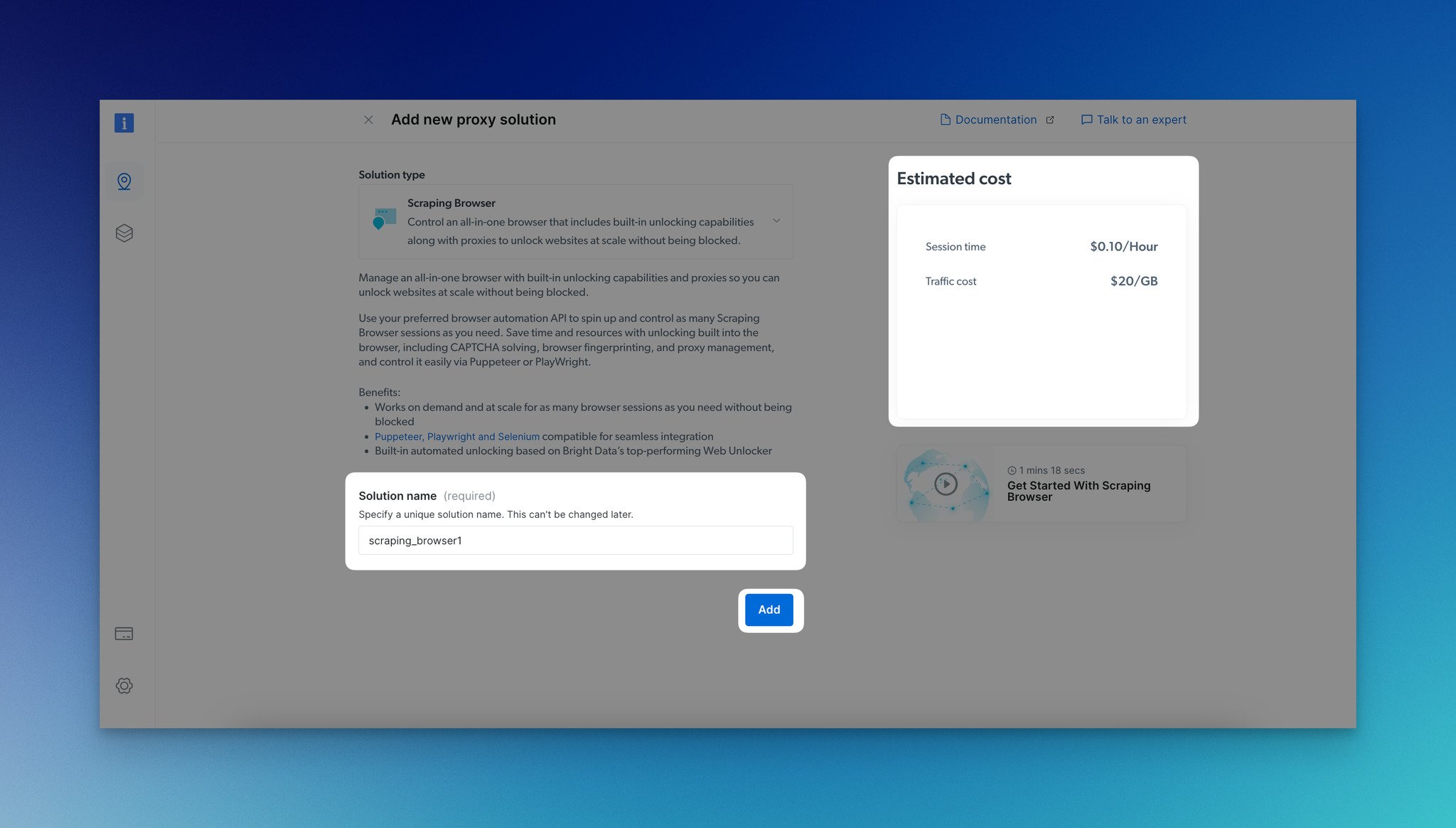
From the right side, you can see the estimated cost with details like session time and traffic cost.
Step 3: Then, you will be redirected to the Access parameters page. From this part, you can get the details of the host, username, and password.
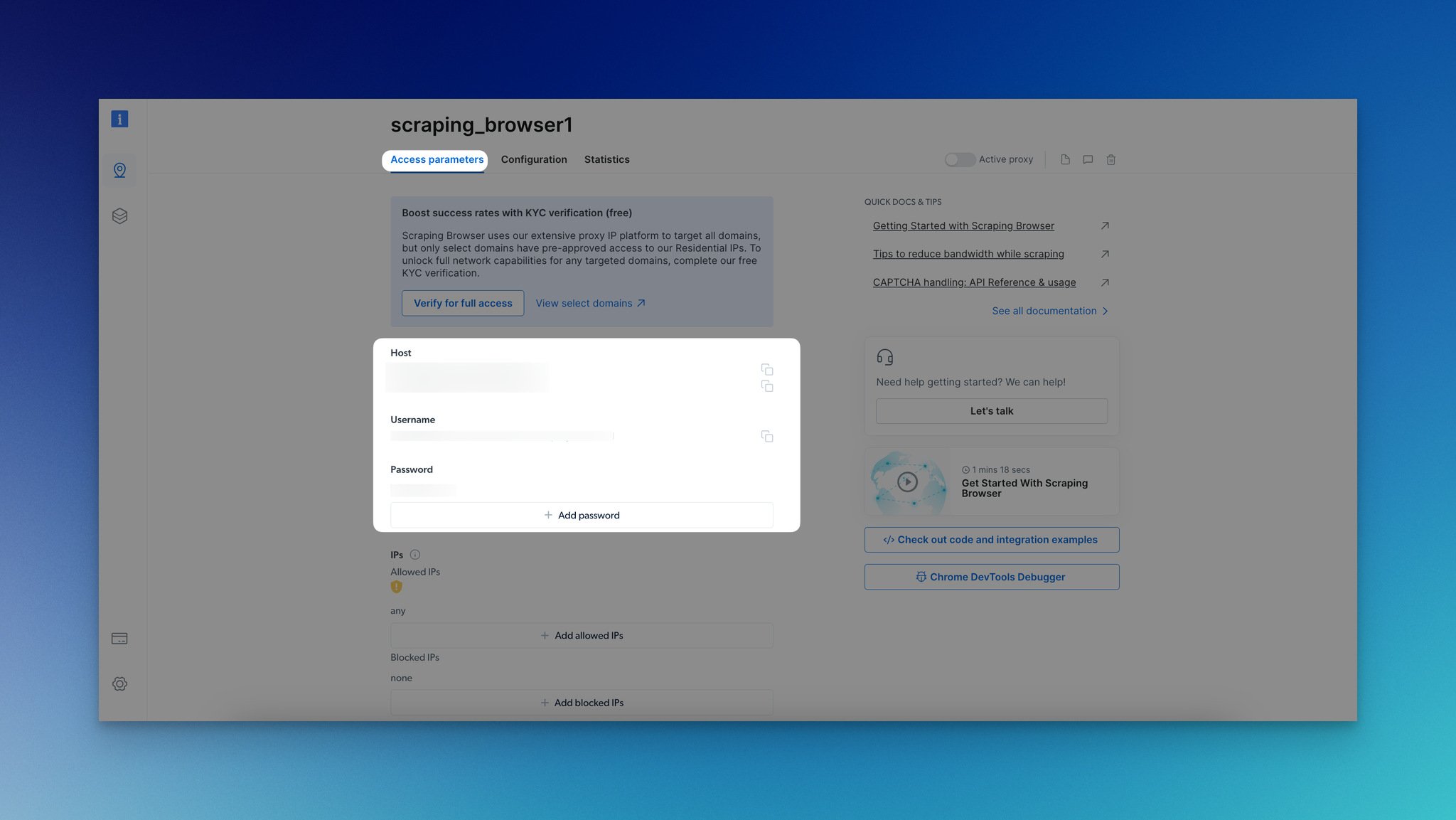
Your Scraping Browser credentials are essential for launching a new browser session.
Ensure that you keep this information secret and safe.
Step 4: By clicking the "Check out code and integration examples" button, you can explore how you can integrate.
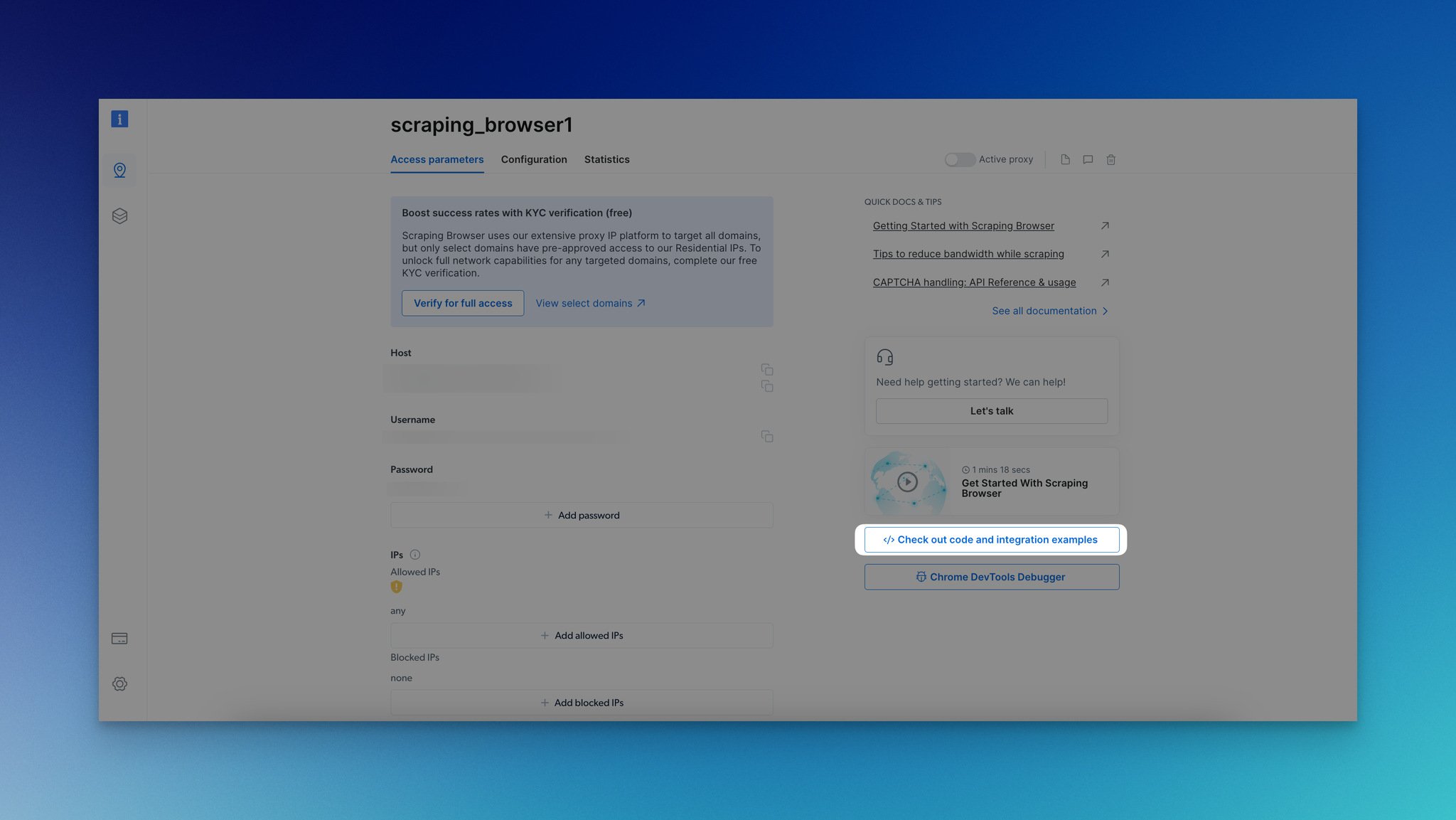
Step 5: From the "Proxy integration examples," you can choose among languages such as Node.js, Python, C#, and libraries which are Puppeteer, Playwright, and Selenium.
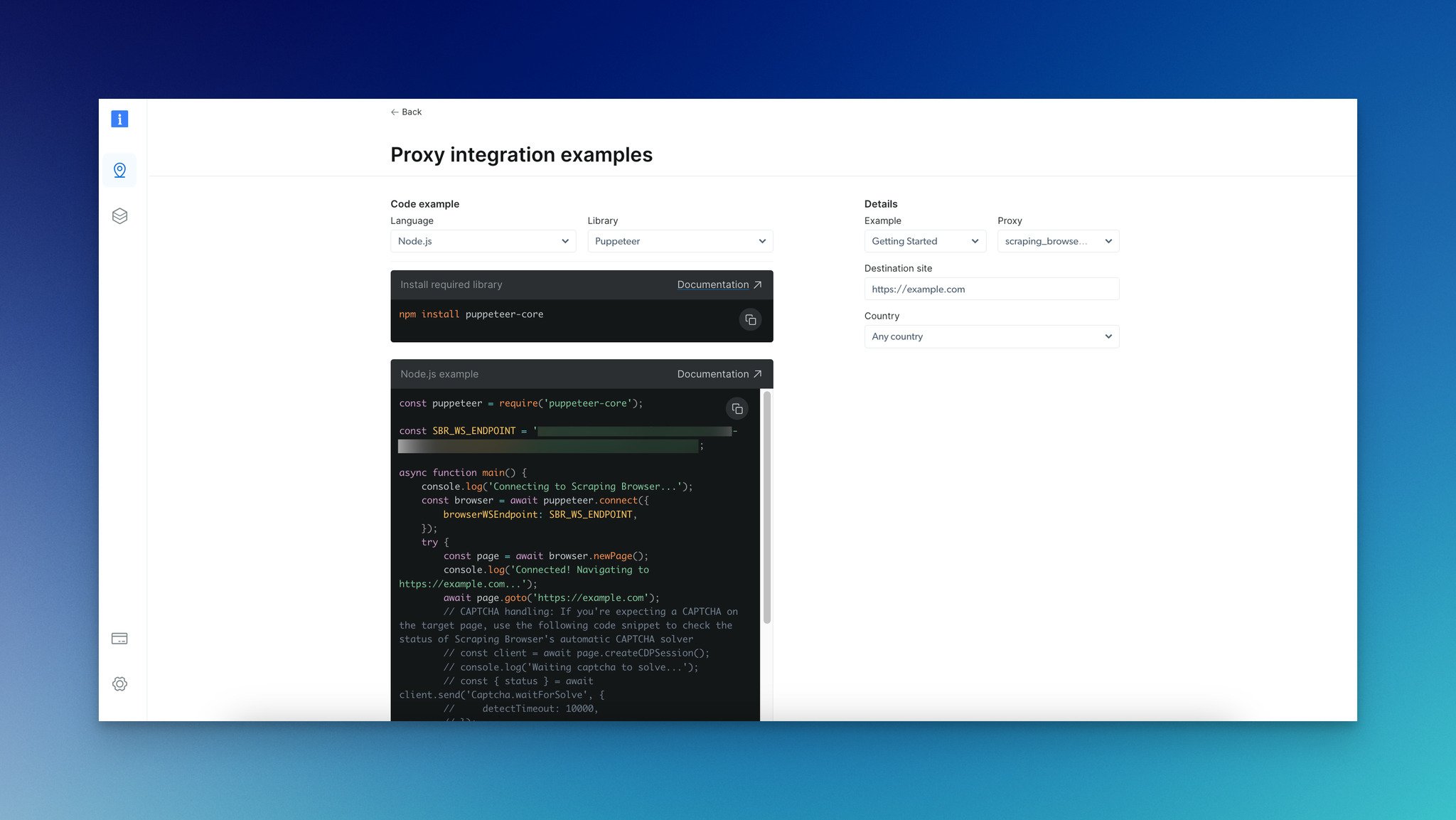
The Scraping Browser functions like other automated browsers, utilizing widely used high-level APIs such as Puppeteer and Playwright. However, it stands out as the only browser equipped with built-in website unblocking features.
Important: To utilize libraries like Puppeteer, Selenium, or Playwright, you need to be familiar with coding and programming languages. Since these steps require technical knowledge, you can refer to these libraries' documentation or consult a developer for better results.
Step 6: You can choose your preferred language and browser navigation library. For this guide, let's choose Puppeteer Node.js.
You need to install puppeteer-core via npm:
Step 7: Run the provided script example (substitute your credentials, zone, and target URL as needed):
Then run the script:
You need to create a simple Node.js application that will navigate to amazon.com as you want to scrape product data from Amazon.
You can write amazon.com next to the "await page.goto" part of the first script we included above.
Then, set your preferred details. For example, you might want to explore product details on Today's Deals page of Amazon. Once you enter the Amazon URL, you can add details like certain texts and actions according to your use cases.
Since use cases of Amazon product data differ, you can optimize this part according to your needs by adding relevant details.
Tip: You can automatically open devtools if you want to view your live browser session. By going back to the Access parameters page, you can use Chrome DevTools Debugger.
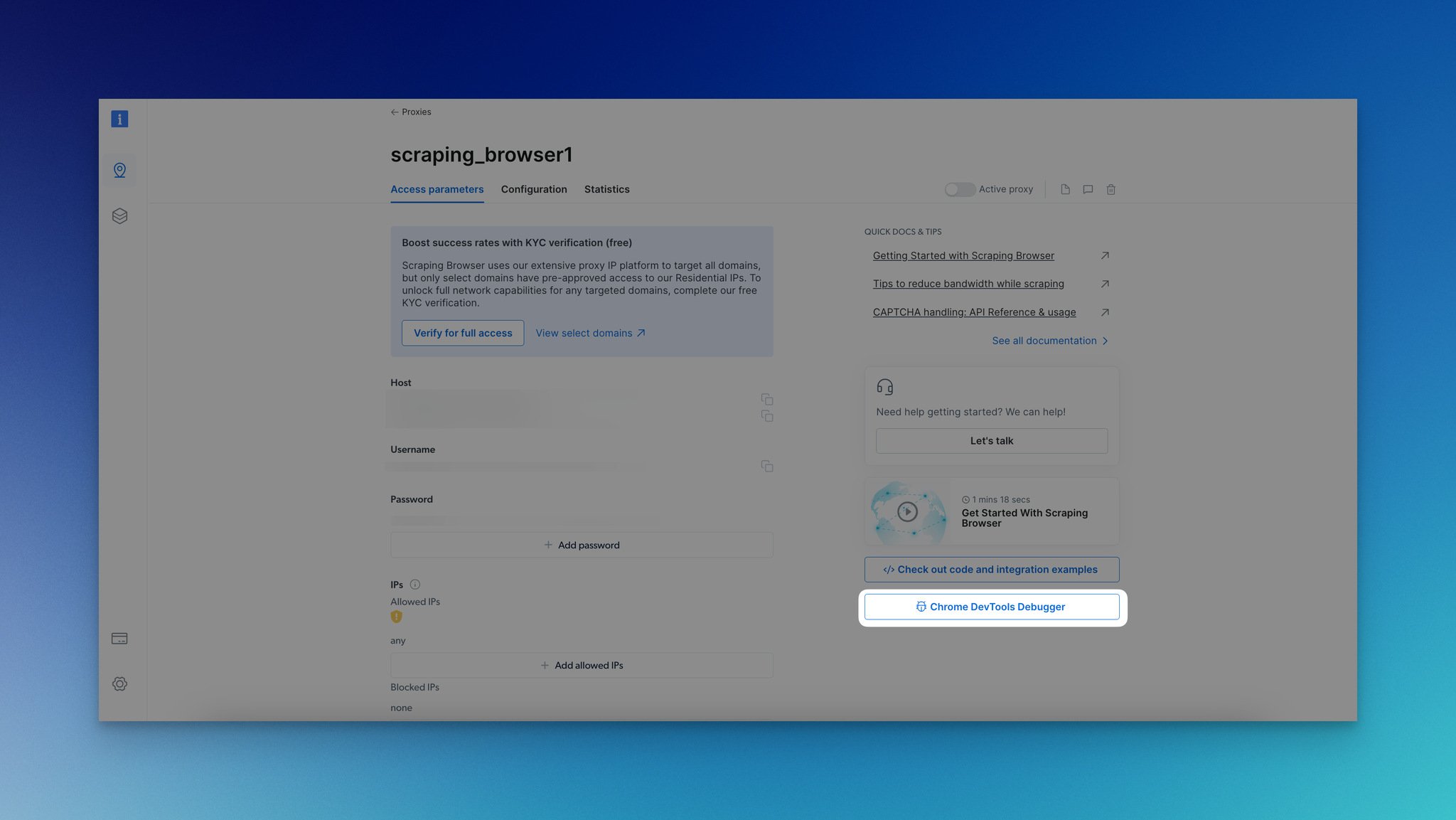
The Scraping Browser Debugger solution helps developers analyze and double-check their code with Chrome DevTools Debugger. That way, users can use these capabilities properly without any errors.
You can use the code snippet below to automatically initiate devtools for each session:
Once you adjusted all the details and optimized your code according to your requirements about scraping Amazon product data, you can start gathering relevant product data.
Important: Since Scraping Browser automatically handles website unlocking operations like CAPTCHA solving, automatic retries, selecting headers, cookies, browser fingerprinting, and JavaScript rendering, you don't have to manage these manually.
Step 8: You can go back to Scraping Browser and navigate to the "Statistics" part to get an overview of metrics, event logs, and access logs.
That way, you can better understand how much it costs to scrape Amazon product data along with valuable metrics.
Usage Areas of Amazon Product Data
There are various usage areas of Amazon product data. You can get valuable insights by scraping Amazon product data and focusing on certain usage areas. Considering your business size, goals, needs, and interests, you can find a suitable usage area for you.
Here are a few usage areas of Amazon product data:
- Business intelligence: Business owners can use Amazon product data to gain insights into market trends, consumer preferences, and competitor strategies. Businesses can make informed decisions to stay ahead of the curve by analyzing pricing, product features, and customer reviews.
- Market research: Researchers can use product data to conduct in-depth market studies, track the rise and fall of product trends, and understand consumer behavior in specific categories.
- Price monitoring: E-commerce businesses can monitor competitor prices and adjust their pricing strategies.
- Content creation: Content creators can use product data to identify popular keywords and trending topics to create engaging content.
- Brand monitoring: Brands can closely monitor how their products are represented, monitoring product listings, customer reviews, and overall brand perception.
- Academic research: Researchers can use scraped Amazon data for various studies, including consumer behavior analysis, the impact of customer reviews on purchasing decisions, and so on.
Benefits of Having Amazon Product Data

Having Amazon product data has various benefits; learning these advantages can help you shape your strategy.
Here we listed the important benefits of having Amazon product data:
- Informed decision-making: Whether you're a business owner determining your product lineup or a researcher analyzing market trends, having accurate and up-to-date Amazon product data can be helpful in informed decision-making.
- Targeted marketing strategies: Amazon product data can provide valuable information for refining marketing strategies. From identifying popular keywords to analyzing successful advertising approaches, businesses can optimize their marketing efforts to reach their target audience more effectively.
- Monitoring competitors' strategies: Businesses can monitor their competitors With insights from scraped Amazon data. Understanding competitor pricing, product features, and customer reviews can guide you to adjust your strategies effectively and respond effectively to market changes.
- Trend analysis: Understanding consumer preferences and emerging trends is crucial for staying relevant. Amazon product data provides information on trending products, allowing businesses to adapt their inventories to meet changing customer demands and interests.
- Pricing optimization & improvements: Strategic pricing is crucial for e-commerce success. By scraping Amazon product data, businesses can track price details in real time, adjust their pricing strategies accordingly, and ensure they stay ahead of their competitors in the industry.
- Improved product offerings: Scraped product data is valuable for product development and enhancement. By analyzing customer reviews and market trends, businesses enhance their existing products or introduce new offerings that resonate with consumer preferences.
- Strategic partnerships and collaborations: For businesses looking to form strategic partnerships or collaborations with other brands or stores, scraped data can be helpful. Having a comprehensive understanding of your market position and potential partners' positions can be great for mutually beneficial agreements.
- Efficient inventory management: Inventory management is essential for preventing stockouts or overstock situations. By scraping data on product availability and sales volumes, businesses can optimize their inventory levels, reduce carrying costs, and enhance supply chain efficiency.
- Customer reviews and feedback: Obtaining customer feedback is important for business improvement. Scraping customer reviews and feedback from Amazon products can provide valuable insights into product satisfaction, pain points, and areas for improvement.
Wrap Up
Scraping Amazon product data can provide many valuable insights about e-commerce. If you are a marketer or an e-commerce store owner, using this information can help you improve your business.
That's why we explained how to scrape data from Amazon in this article with a step-by-step guide. Using this article as a guide, you can quickly gather Amazon product data according to your use cases.
We also included different usage areas and benefits of having product data so that you can get a better understanding while creating your strategies. That way, you can get the full potential from scraped product data.
Frequently Asked Questions

Is It Legal to Scrape from Amazon?
Scraping Amazon can potentially violate Amazon's terms of service, so it's essential to review and comply with their policies. Focus on prioritizing ethical scraping practices, respect the website's terms, and avoid unauthorized scraping to stay within legal boundaries.
How to Handle CAPTCHAs and Anti-Scraping Mechanisms?
To overcome CAPTCHAs and anti-scraping measures, consider using headless browsers, solving CAPTCHAs manually, or integrating CAPTCHA-solving services. Additionally, employing techniques like user-agent rotation and proxy usage can help reduce the risk of detection.
Which Tools Can Be Used for Scraping Amazon Product Data?
There are popular libraries for scraping Amazon, such as Puppeteer, BeautifulSoup, Scrapy, and Selenium. These libraries can be used for the extraction of data from Amazon. You can choose a tool based on your programming language preferences and library familiarity.
You can also use web scraping tools to scrap Amazon product data. Tools like Bright Data, Oxylabs, and Apify can help you speed up the process with their useful capabilities.
Discover these blog posts before you go:




